
The three level of data modeling:-
conceptual data model
A conceptual data model identifies the highest-level relationships between the different entities. Features of conceptual data model include:
· Includes the important entities and the relationships among them.
· No attribute is specified.
· No primary key is specified.
logical data model
A logical data model describes the data in as much detail as possible, without regard to how they will be physical implemented in the database. Features of a logical data model include:
· Includes all entities and relationships among them.
· All attributes for each entity are specified.
· The primary key for each entity is specified.
· Foreign keys (keys identifying the relationship between different entities) are specified.
· Normalization occurs at this level.
The steps for designing the logical data model are as follows:
1. Specify primary keys for all entities.
2. Find the relationships between different entities.
3. Find all attributes for each entity.
4. Resolve many-to-many relationships.
5. Normalization.
physical data model
Physical data model represents how the model will be built in the database. A physical database model shows all table structures, including column name, column data type, column constraints, primary key, foreign key, and relationships between tables. Features of a physical data model include:
- Specification all tables and columns.
- Foreign keys are used to identify relationships between tables.
- Denormalization may occur based on user requirements.
- Physical considerations may cause the physical data model to be quite different from the logical data model.
- Physical data model will be different for different RDBMS. For example, data type for a column may be different between Oracle, DB2 etc.
The steps for physical data model design are as follows:
- Convert entities into tables.
- Convert relationships into foreign keys.
- Convert attributes into columns.
- Modify the physical data model based on physical constraints / requirements.
Here we compare these three types of data models. The table below compares the different features:
Feature
|
Conceptual
|
Logical
|
Physical
|
Entity Names
|
✓
|
✓
| |
Entity Relationships
|
✓
|
✓
| |
Attributes
|
✓
| ||
Primary Keys
|
✓
|
✓
| |
Foreign Keys
|
✓
|
✓
| |
Table Names
|
✓
| ||
Column Names
|
✓
| ||
Column Data Types
|
✓
|
Conceptual Model Design

Logical Model Design
 Physical Model Design
Physical Model Design



We can see that the complexity increases from conceptual to logical to physical. This is why we always first start with the conceptual data model (so we understand at high level what are the different entities in our data and how they relate to one another), then move on to the logical data model (so we understand the details of our data without worrying about how they will actually implemented), and finally the physical data model (so we know exactly how to implement our data model in the database of choice). In a data warehousing project, sometimes the conceptual data model and the logical data model are considered as a single deliverable.
Conclusion:
Conceptual, logical and physical model or ERD are three different ways of modeling data in a domain. While they all contain entities and relationships, they differ in the purposes they are created for and audiences they are meant to target. A general understanding to the three models is that, business analyst uses conceptual and logical model for modeling the data required and produced by system from a business angle, while database designer refines the early design to produce the physical model for presenting physical database structure ready for database construction.
With Visual Paradigm, you can draw the three types of model, plus to progress through models through the use of Model Transitor.
Conceptual Model
Conceptual ERD models information gathered from business requirements. Entities and relationships modeled in such ERD are defined around the business's need. The need of satisfying the database design is not considered yet. Conceptual ERD is the simplest model among all.
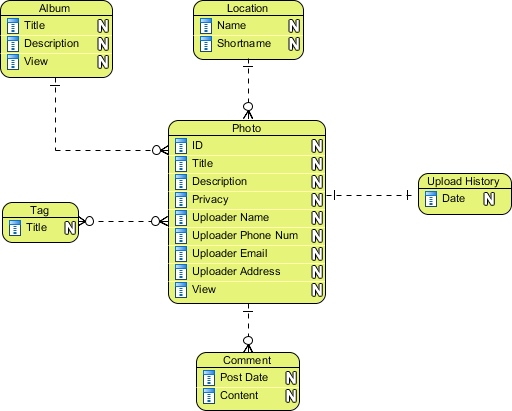 |
| Conceptual ERD example |
Logical Model
Logical ERD also models information gathered from business requirements. It is more complex than conceptual model in that column types are set. Note that the setting of column types is optional and if you do that, you should be doing that to aid business analysis. It has nothing to do with database creation yet.
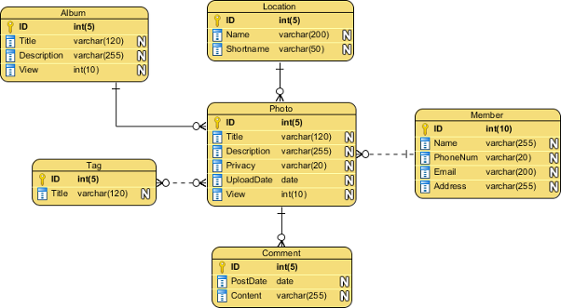 |
| Logical ERD example |
Physical Model
Physical ERD represents the actual design blueprint of a relational database. It represents how data should be structured and related in a specific DBMS so it is important to consider the convention and restriction of the DBMS you use when you are designing a physical ERD. This means that an accurate use of data type is needed for entity columns and the use of reserved words has to be avoided in naming entities and columns. Besides, database designers may also add primary keys, foreign keys and constraints to the design.
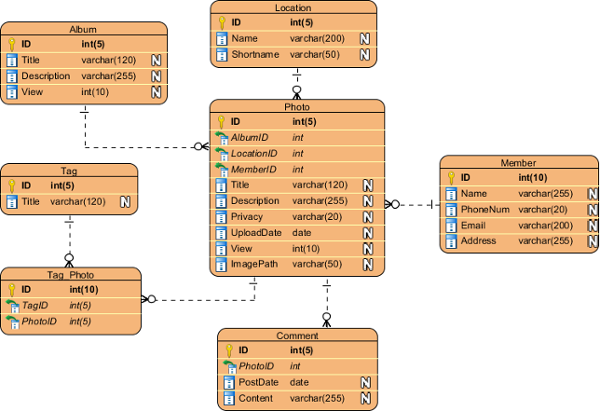 |
| Physical ERD example |









